
Lambda Docker Adventures with SQLite

Last year I spent some time playing around using Tegola (a mapping tile generator) and AWS Lambda to generate map tiles using Geospatial data stored in SQLite and hosted on Amazon EFS. There was a serious performance penalty reading large data files over EFS, so I needed to make sure my database was as small as possible. In addition, you pay for all that data that you’re transferring, so although not expensive for a low volume site, you could end up in a pickle if things pick up.
To further that thread of SQLite data in Lambda, in December last year as an early Christmas present AWS released Container Image support, a sort of half-way between a traditional Lambda Zip function and a ECS-Fargate container. This allows you to generate a Docker image locally, push it into the Elastic Container Registry (ECR), and then use that as a Lambda function. Cool, but what really caught my eye was the fact that it supports up to a 10Gig container image. So, was using Docker+Lambda a better solution for read-only SQLite databases than Lambda+EFS? I wanted to build out something practical to validate the technique, so I decided on an address auto-complete endpoint, where it turns free text into decomposed address data. For example, if you supply “101 Coll” as text, I want it to return the decomposed address information for “101 Collins Street”.
G-NAF Fun with SQLite

The data I was using last time originated from the Australian Government’s Geoscape Geocoded National Address File (G-NAF), which contains a record of every single physical address in Australia. The data itself is provided in a pipe-seperated set of normalized files, which are easily loadable into Postgres/Postgis with the included set of table schemas; once you get around the table structure.
Now I wanted to load this address data into SQLite, so I needed to make a couple of less-than-ideal modifications to the standard load process:
- Schema Refactor: SQLite needs its foreign keys defined upfront, so I needed to modify the included G-NAF schema for that.
- Null Imports: This took me far longer than I care to admit to fix(and I only identified it as an issue later), but there is currently no mechanism to have SQLite’s default CSV import mechanism to treat blank values as nulls. So my database import was originally littered with empty char fields. I ended up using a blunt hammer to update all empty strings to NULL through a set of SQL UPDATE commands; not pretty, but it works. Also very slowwww.
The end product is this enormous Docker Image (https://hub.docker.com/repository/docker/ggotti/g-naf-full-sqlite), based off this Github repository. It’s a great way of being able to quickly see what G-NAF has to offer, without needing to fumble around with the schema.
Distilling it Down
With my frankenstein SQLite image, it was time to convert that into something I could use in my Lambda function. I created a new SQLite database, and then I materialised the “ADDRESS_VIEW” from the G-NAF schema into a separate table in my new database, which is effectively a denormalized view of the address data.
The next step was to create a text representation of the address data. The excellent team at ISP Superloop have come up with a MySQL version of converting the data into text. Unfortunately, it makes extensive use of `CONCAT_WS`, which again is something not supported by SQLite. What I ended up doing was hand converting their statement into an absolutely unmaintainable mess of a thing, which sort of replicates the `CONCAT_WS` behaviour using syntax that’s available. It’s not 100%, but it’s close enough. Look at this horrific mess. Warning. May Burn your Eyes Out.

AWS SAM supports the build and development of Docker Images as part of the CLI. I ended up using that to build the project scaffold, and then introduced a multi-step Docker Build process to pull in the SQLite image, generate the distilled address database, and then copying the generated database into the appropriate NodeJS Lambda docker image: public.ecr.aws/lambda/nodejs:14. I was originally building this on my 2015 Macbook Pro, and it was seriously struggling with my grotesquely unoptimised build process. I ended up switching it to an older Linux desktop, but it didn’t struggle as much with the heavy disk IO.
SAM itself is really getting better and better with every release. It’s
so quick to just spin up a new application. The only thing I had to do
outside of SAM was define the Elastic Container Repository (ECR), and
just feed those details into SAM. sam build && sam deploy and you’re
good to go.
Demo

The Lambda application itself is pretty simple, with a small JavaScript application connecting to SQLite and doing a LIKE search against one of the tables. This could probably be improved with the FTS5 Full Text Search extension, but LIKE works well enough for this demo. To demo it’s usage, I put a simple web-page using autoComplete.js to hit the Lambda function as the user types. Give it a try here, or watch the above video.
Source code can be found on Github here.
Revisiting Tegola
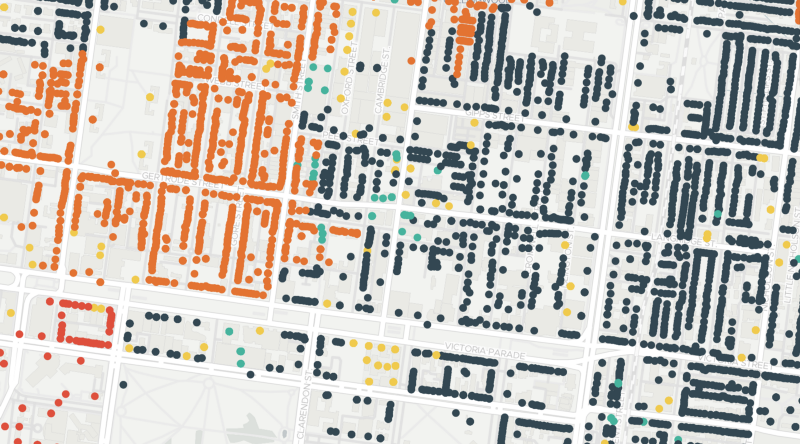
So the real question is, how does the Docker-Image approach work in comparison to reading large SQLite databases off EFS? The results may surprise you. I left the RAM the same (3008mb), and then ran a comparison between the two, against the set of same Tagola coordinates; a rather complex area of the Melbourne CBD. I manually adjusted the RAM between requests, to guarantee a fresh instance of the function. The Lambda first function was consistently taking 25–26 seconds to process the request. Whereas the Docker image was taking between 22–24 seconds to process, when it worked. A large number of requests were hitting the API Gateway’s 30 second limiter, and therefore timing out. There seemed to be a slight delay when the Image was being pulled for the first time, which may factor into the delays. I suspect behind the scenes it does some caching between ECR and Lambda of the image itself, independent of the actual Lambda execution “warmth” behaviour. Increasing the amount of available RAM to 4GB seemed to improve performance consistently.
So there seems to be a slight increase in the RAM requirements for the Docker image. However, the usability of the Docker format for pushing data in, and the fact that the ECR data transfers within the same region are free, make the Docker option pretty appealing.
Conclusion
So, can you use SQLite with Docker in Lambda? You can. Can you import G-NAF data into a relatively compact SQLite database? You can. So is it worth it in the end? The experience with SAM is pretty seamless, and it’s a great way of pushing large read only data images around; less than 10GB currently supported. It certainly removes some of the complexity of managing the data via EFS. Just be prepared to pay a little more on your execution costs running it via Docker.
PS: If you were fully crazy you could probably build some kind of updatable website where you have a separate Lambda function updating an ECR image based off a singular write data fed in via an SQS queue. Maybe.